
Semantic Resume Screening
Reduced turn-around-time by 90% for Mopid's clientele by developing an advanced resume data extraction method and re-ranking algorithm.
The How:
Instead of the usual keyword match approach from job description to resume for filtering out candidates, I created a method to extract more insights from a resume and an algorithm that made the process of shortlisting the right candidate for a job faster without the need for human intervention.
My Contribution:
Discovery
Identified bottleneck in the candidate screening flow by observing the process and speaking with the operations team.
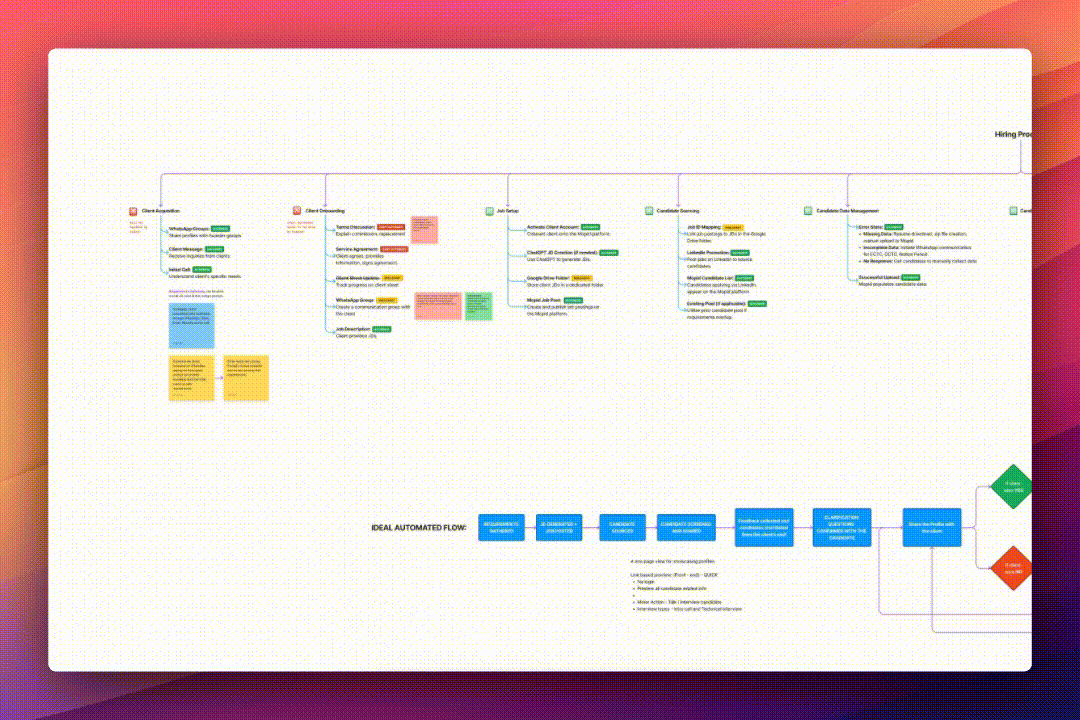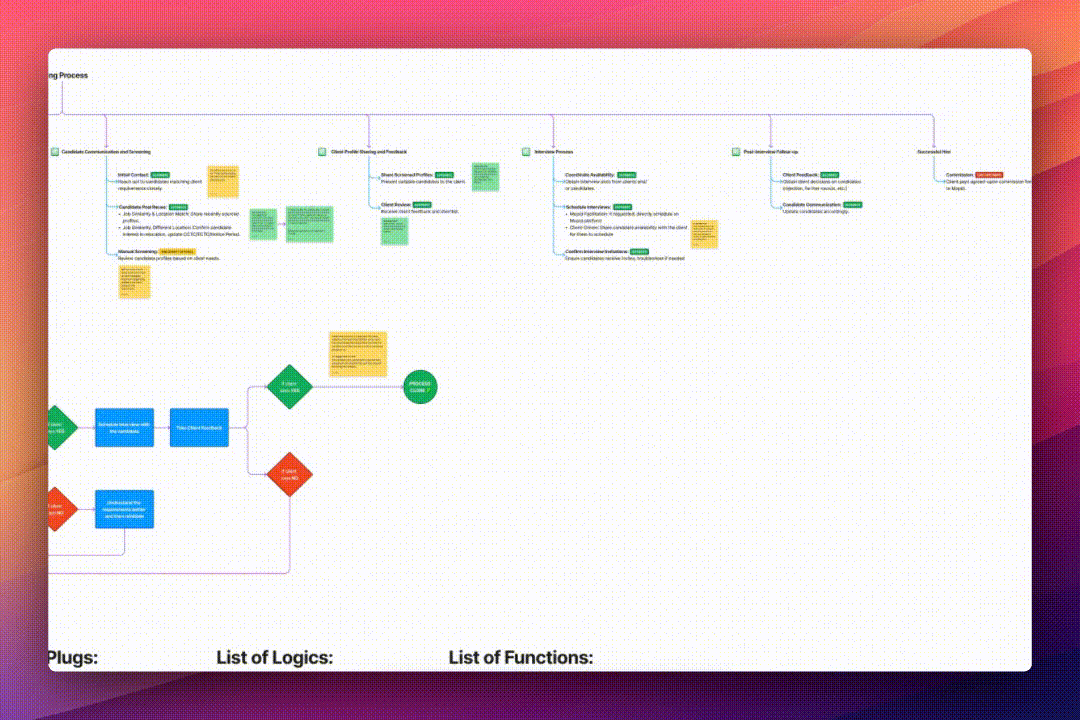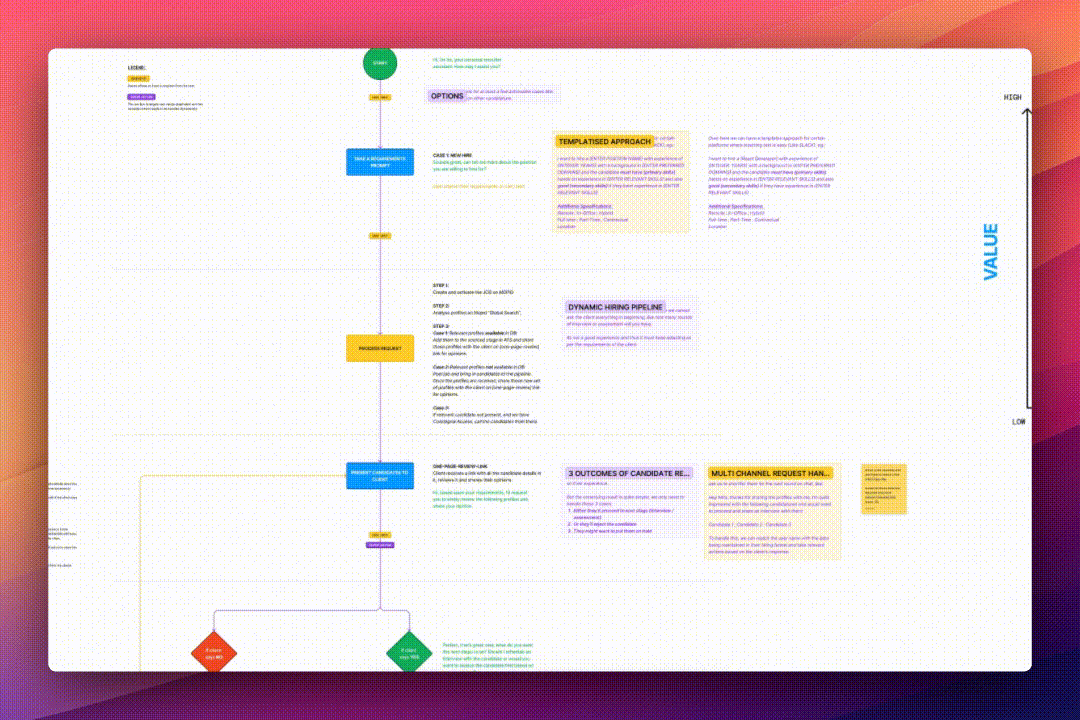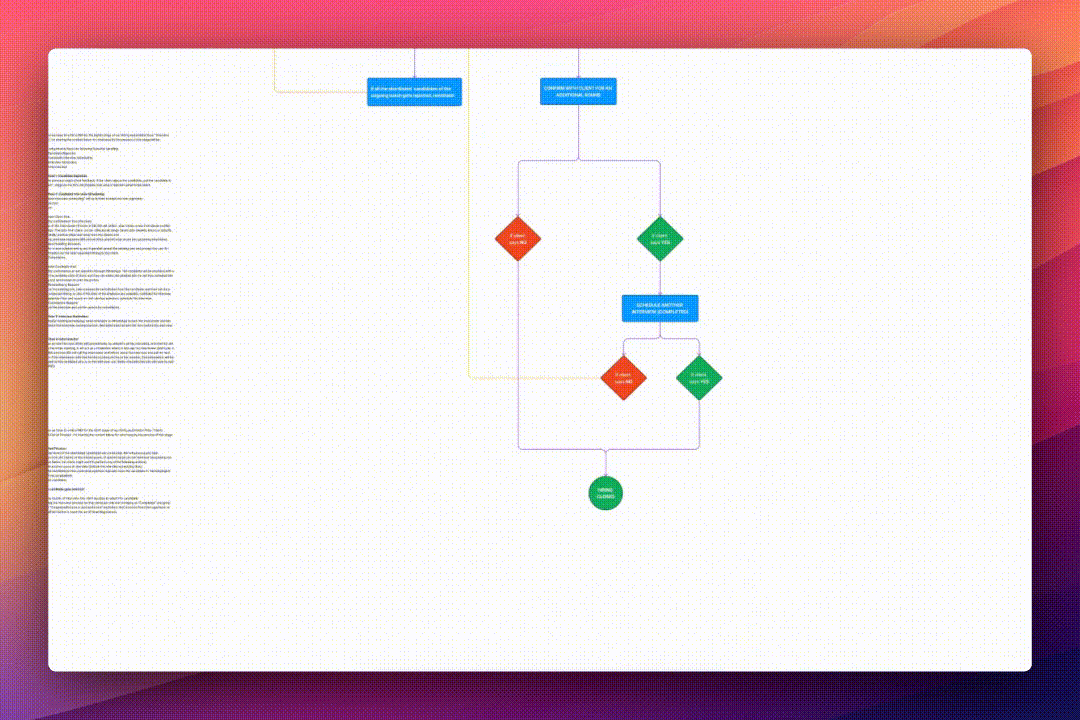
Development
- Developed a JSON schema capable of storing categorized resume information.
- Created a prompt for analyzing and extracting categorized resume data.
- Coded a Python application to generate and store resume data embeddings in a vector database, enabling a semantic search index using Google’s Vertex AI platform.
- Developed rules for an algorithm that re-ranks candidates with human-level accuracy.
Delivery
- Guided the engineering team to implement the entire application flow on our existing database by researching compatible, cost-effective solutions.
- Acted as Product Owner in SCRUM-based sprints, successfully shipping the feature in 6 weeks.
The Process:
CONTEXT
Mopid is a hiring automation platform that helps customers efficiently hire people from various domains at all levels by reducing redundant, resource-intensive processes and personalizing the candidate pool according to specific hiring needs.

PROBLEM
Mopid’s candidate screening flow has a high turnaround time, suggesting issues that cause customers to leave without closing a position through our platform, resulting in reduced revenue.
OPPORTUNITIES
To reduce the turnaround time to present relevant candidates, I considered two main options:
- Method 1: Streamline the candidate screening flow, enrich the data extracted from resumes and make the data semantically searchable.
- Method 2: Categorize the resumes in the candidate pool into relevancy buckets based on domains and further nest them by experience level.
After analyzing the quality of candidates in our talent pool and surveying recruiters, I found that 60% of hiring managers preferred using their own candidate data or collecting new data via various job boards on our platform. Based on these insights, I prioritized ‘Method 1’ to streamline the candidate screening process, which also helped enrich our candidate database and speed up the process.
ACTIONS
To reduce turn-around-time at Mopid, I decided to create a candidate screening process that uses technology instead of human resources by implementing the following methods:
- Enriched Resume Data: I collected multiple resumes from different domains and levels, identifying the types of information they contained. Based on this research, I created a JSON Schema (a language that defines the structure, content, and meaning of JSON objects) to store resume data in a categorized format.
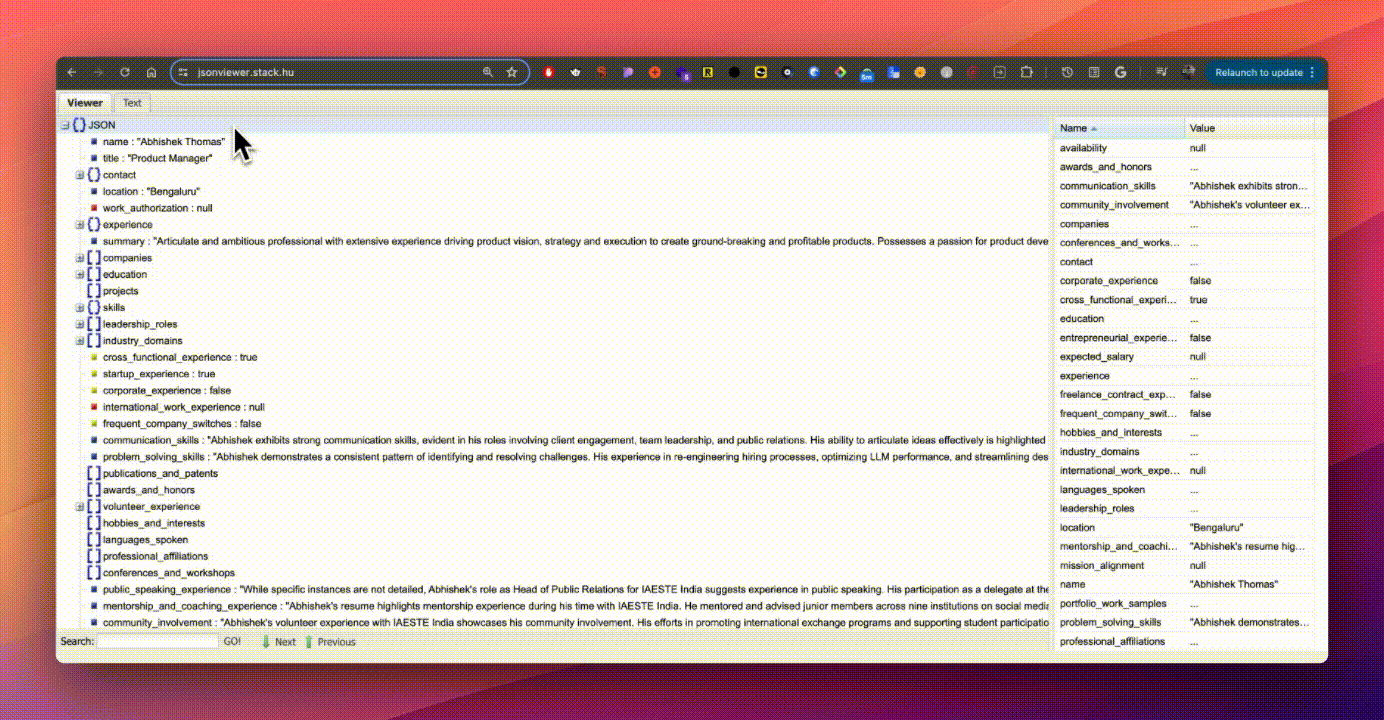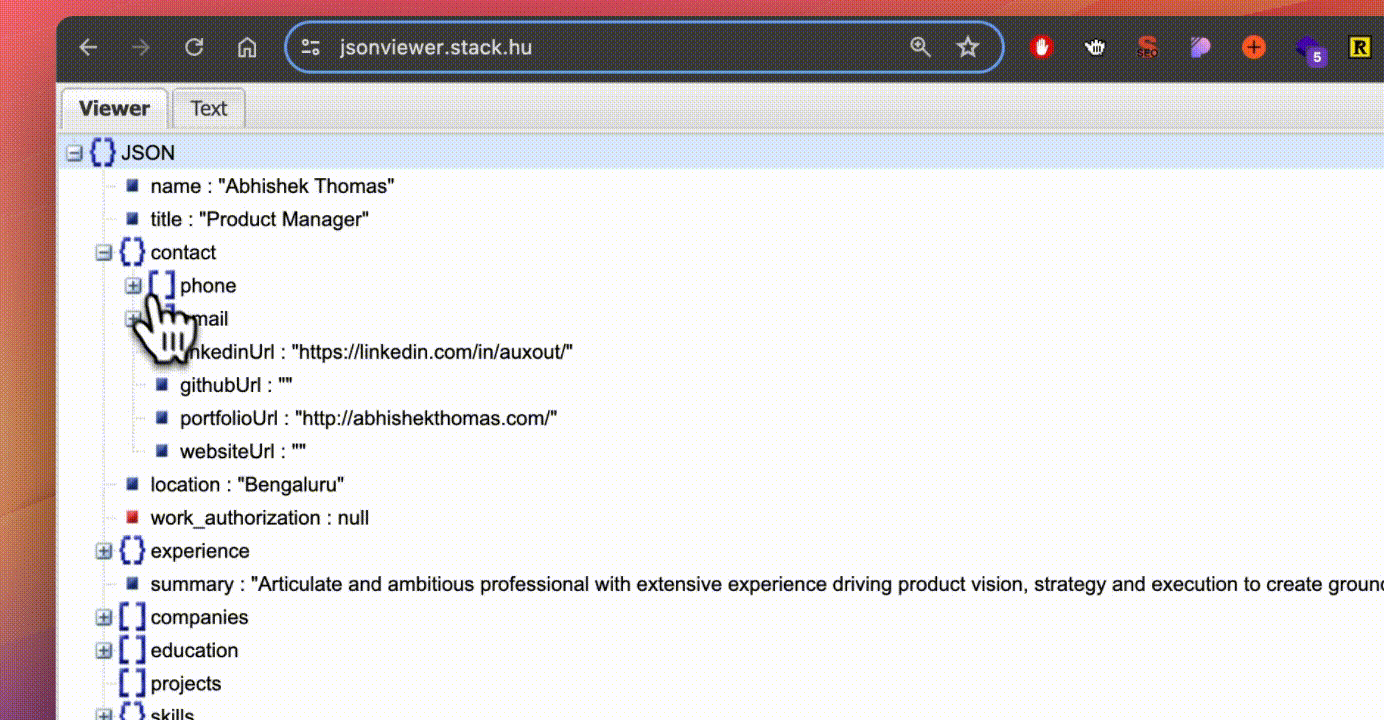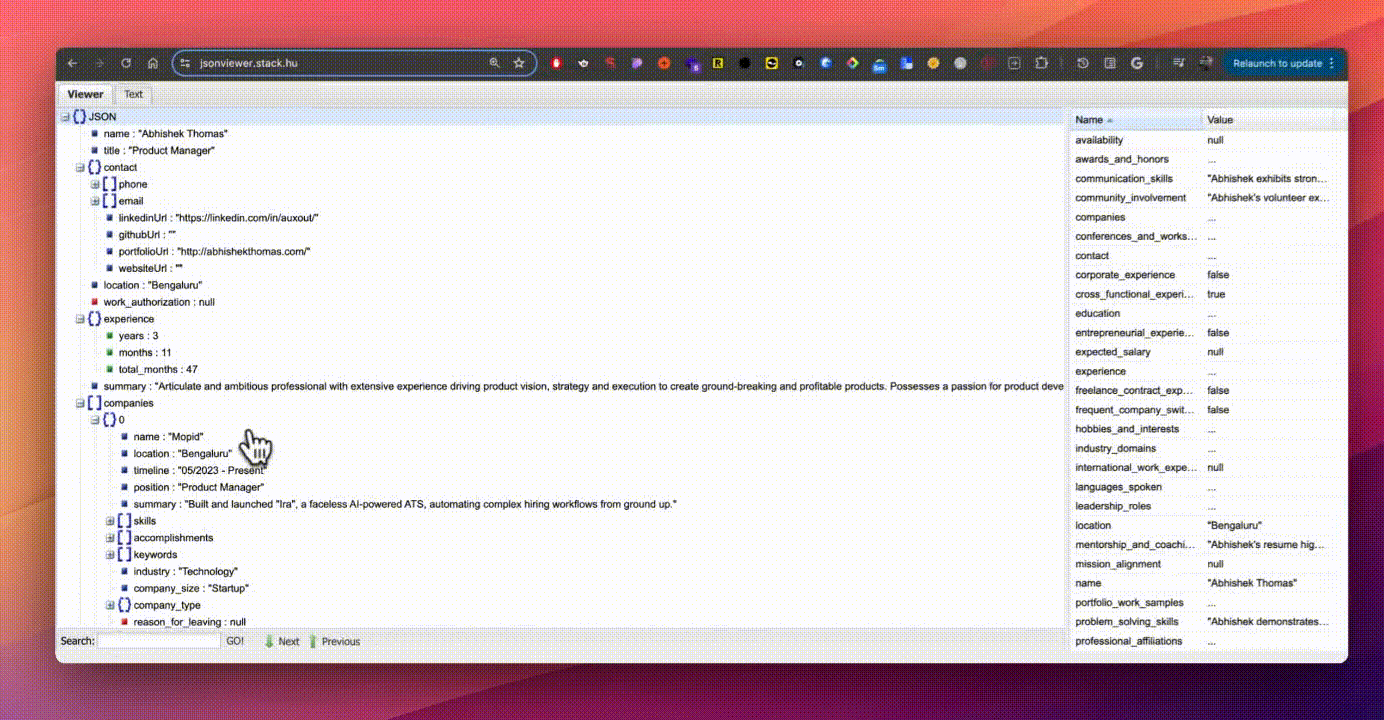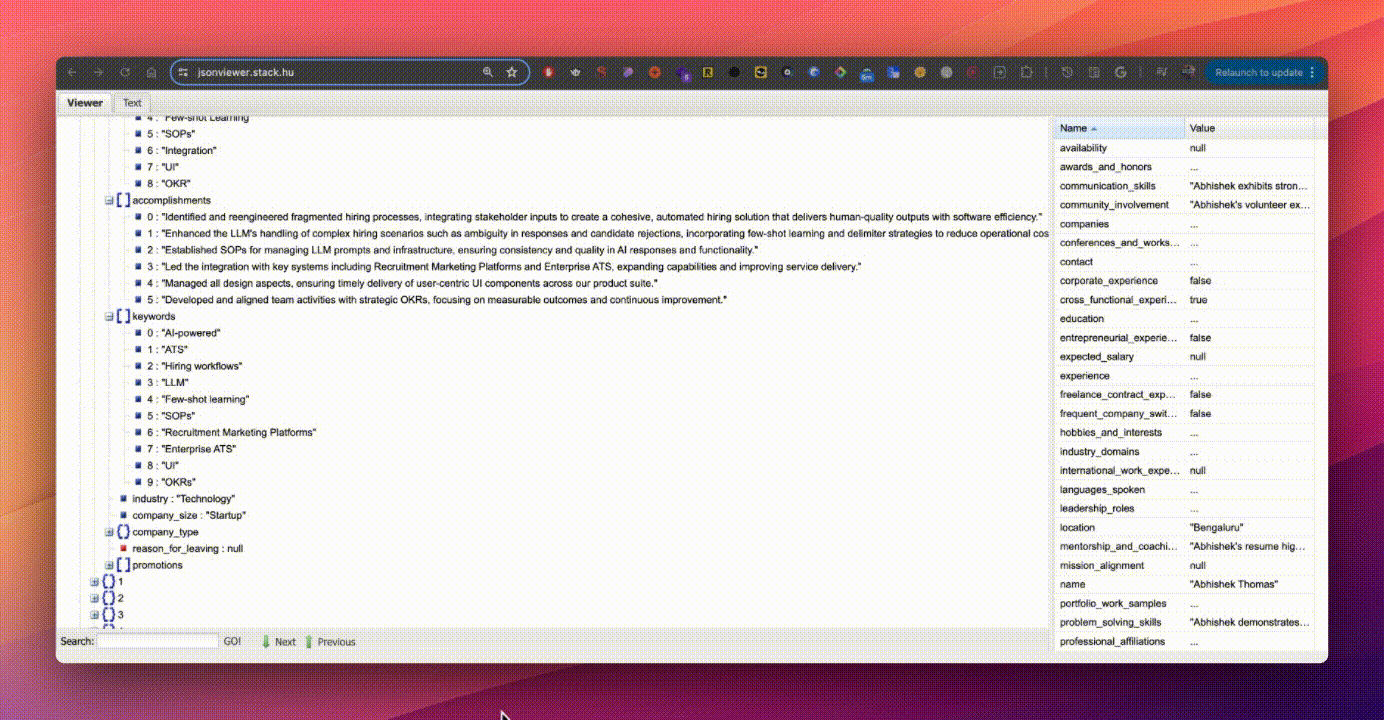
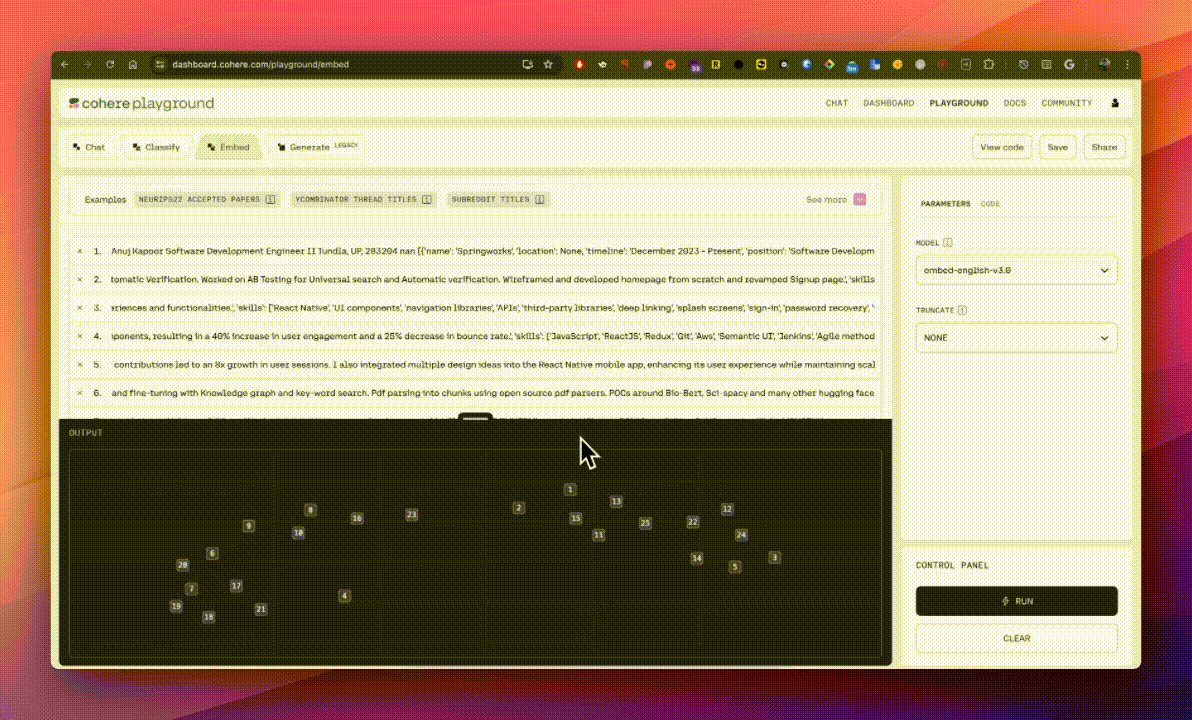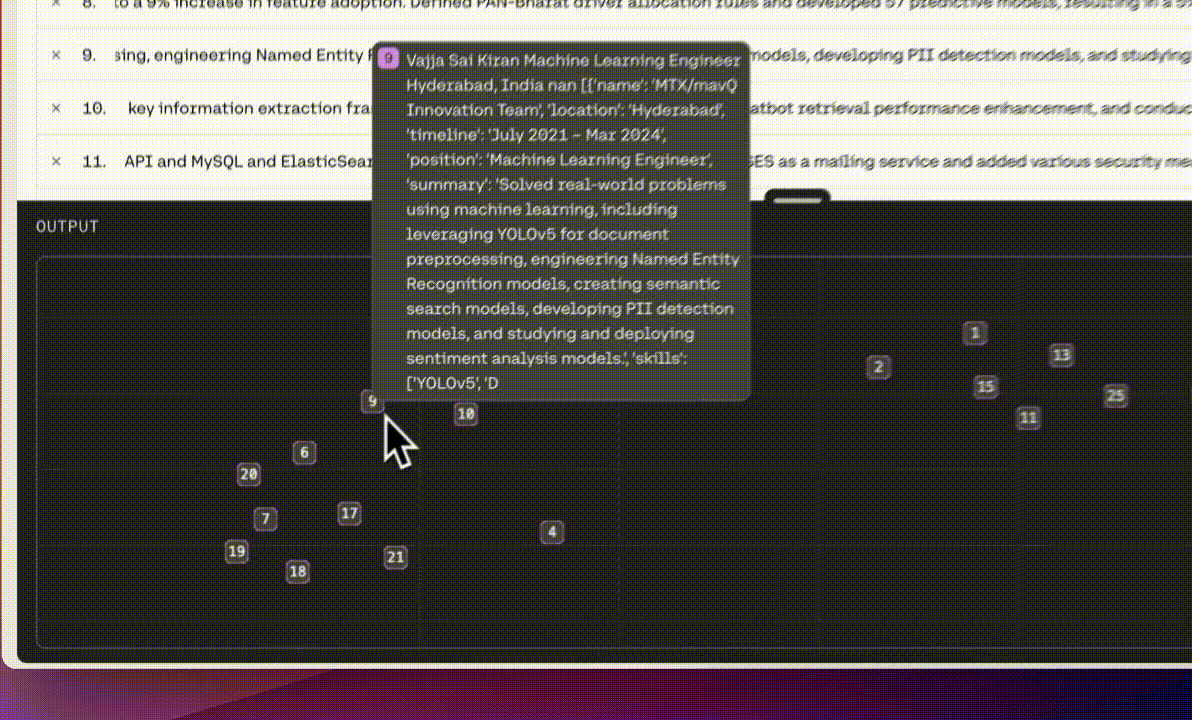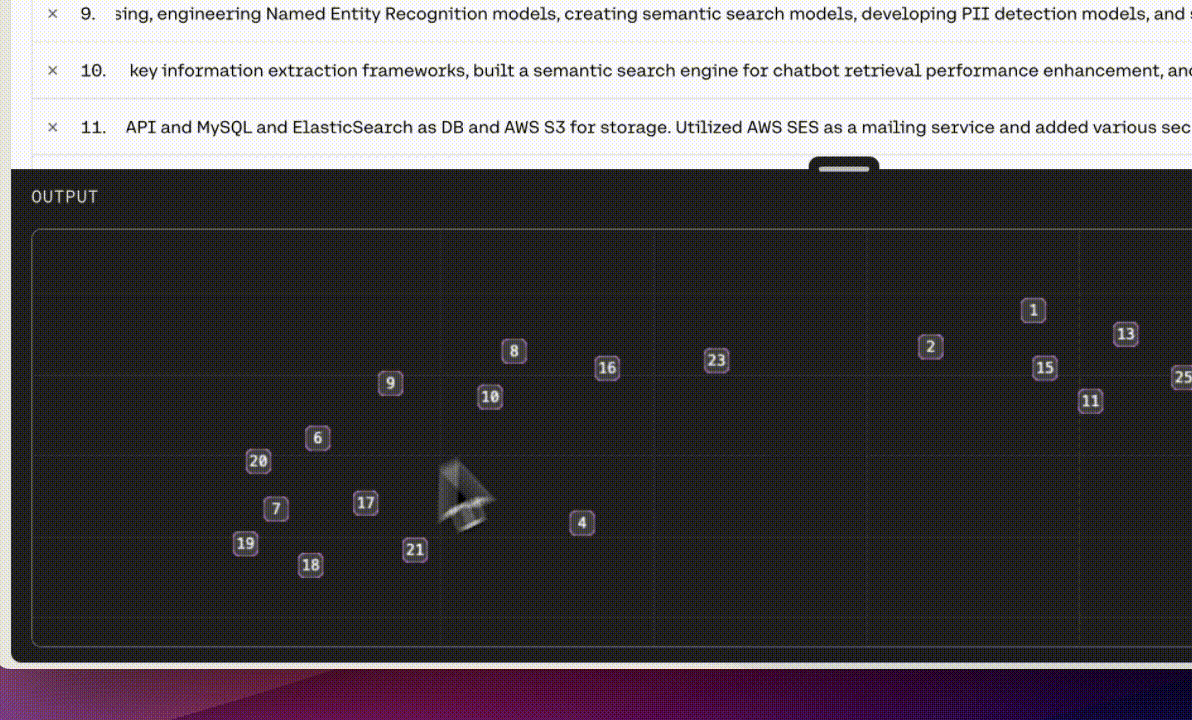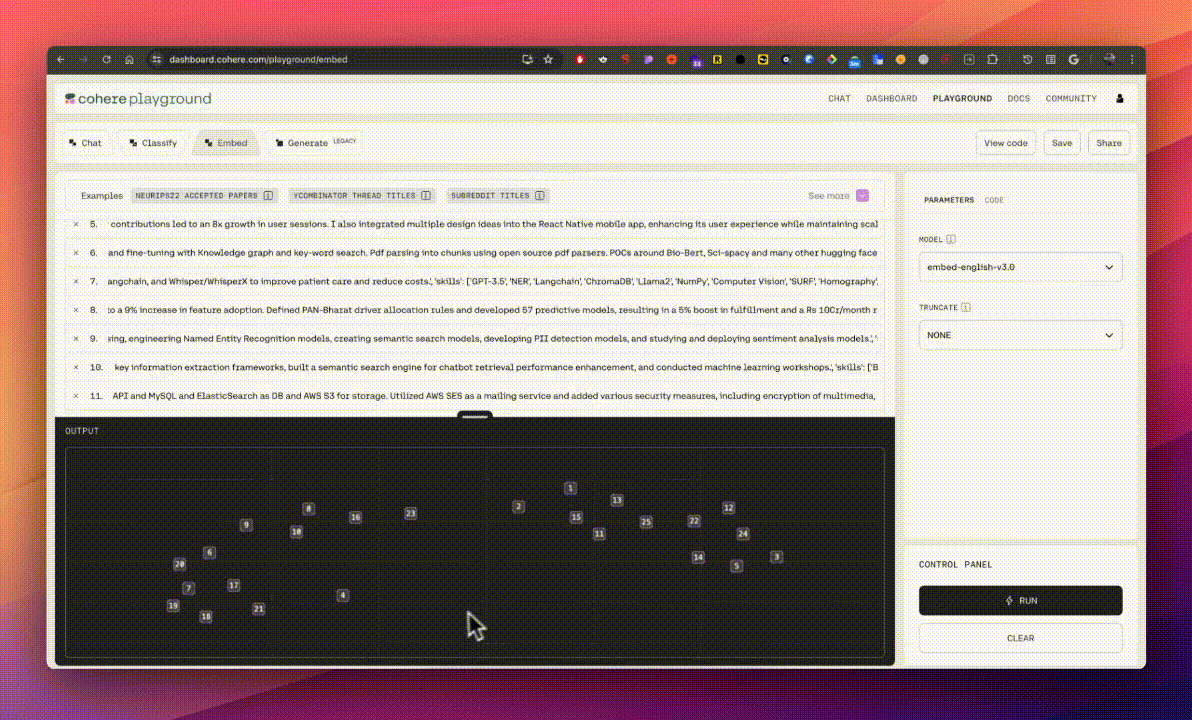
- Created Semantic Index: Researched and discovered that one of the fastest ways to query a huge amount of data is by using a vectorized database, which processes many pieces of data simultaneously and utilizes embeddings for efficient semantic search, speeding up queries which ultimately resulted in faster retrieval of relevant candidate profiles.
- Candidate Re-Ranking: To present the most relevant candidates at the top based on hiring requirements, I developed rules for an algorithm that assigns weights to multiple parameters (Details cannot be shared due to NDA. Contact me for more information) for re-ranking profiles based on the intent of the requirements.
- Natural Language Query Processing: To be able to query the right candidates while keeping the user experience painlessly simple, I decided to introduce a layer of LLM that I had fine tuned for the categorised resume data to be able to take input in natural language, process the intent, and query the right candidates in one go without needing multiple iterations.
RESULTS
The implemented method reduced the turn-around-time by 90%, exceeding the 60% target. The new candidate screening process improved user-friendliness, reduced the operations team’s workload, enriched our candidate pool, and enhanced the customer experience, leading to increased revenue and satisfaction.